

I never liked prompts such as “be my strategist” or “be the skeptic” or “you are a consultant on this topic.” They always felt weak to me, full of implicit assumptions that nobody examines.
You tell your LLM: “Imagine you are a successful B2B SaaS copywriter.” And you think you’ll access the entire knowledge of copywriting into that one sentence. You think the model will now just be the best copywriter. But that’s not true, because there are so many different copywriters. Their skills vary, their methodologies vary, what they focus on and how they approach a problem is wildly different from one professional to the next. So by saying “be my copywriter,” you’re basically saying nothing.
This is the core problem with persona-based prompts: you’re telling the LLM who to be, instead of how to think. And the result is predictable. After “be my skeptic,” the model sounds skeptical. After “be my empathetic coach,” it sounds warm. After “be my strategist,” it sounds strategic. But sounding like something and actually doing the cognitive work of that thing are very different. You never know what the model encodes behind these labels, or how that encoding shifts between contexts.
What I wanted was something else entirely: a way to co-think with Claude and get multiple perspectives on the same problem. I wanted real perspectives that push against each other, not just tonal variations. And I couldn’t get that from the flat "be my [something]" approach.
So I stopped using lazy prompts telling Claude who to be, and I focused on designing cognitive functions that would tell Claude what kind of thinking to perform.
That’s the first Claude Skill I ever created. I encoded a reasoning protocol with four seats. But instead of personalities, each seat is an irreducible analytical lens.
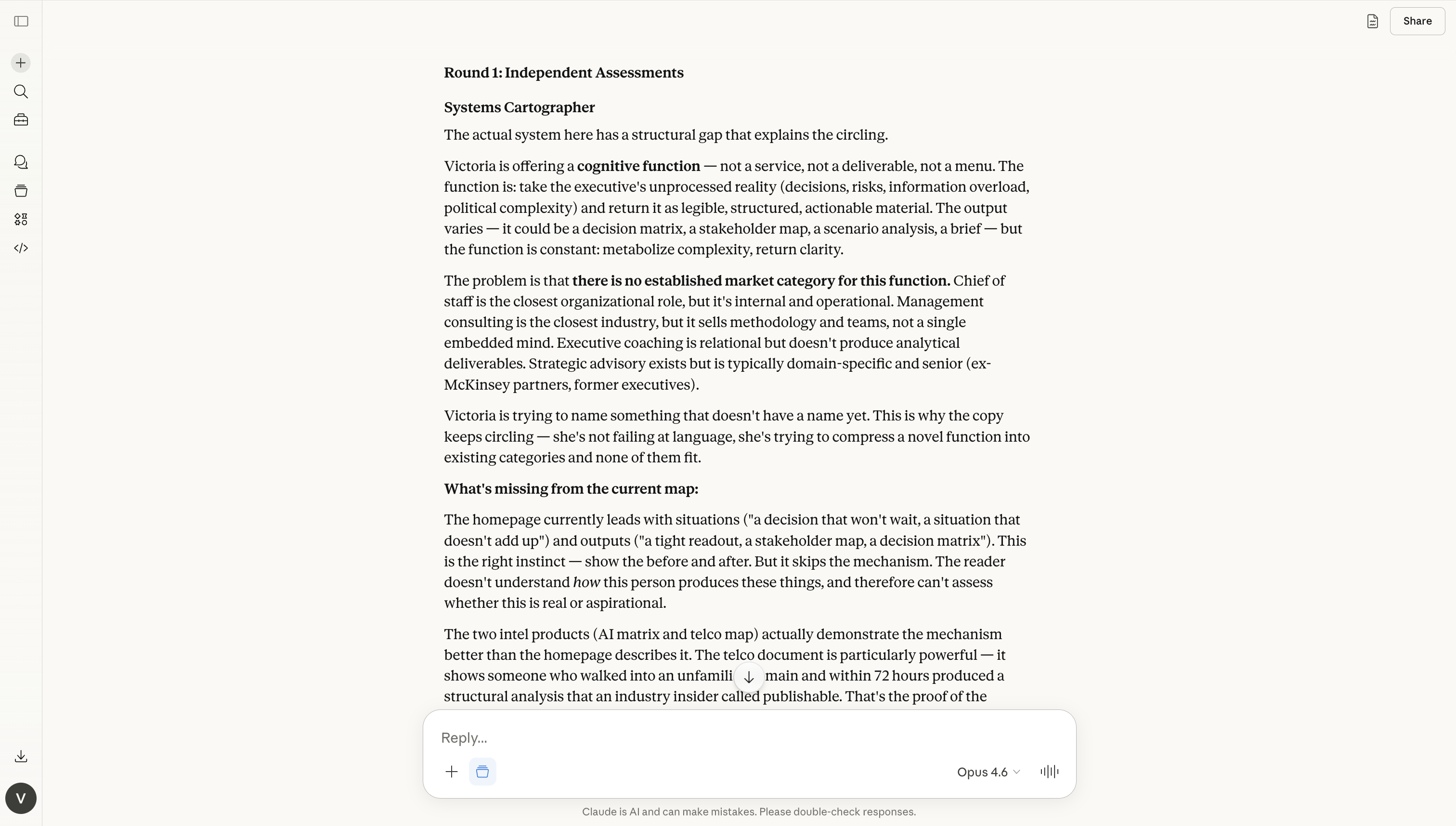
The systems cartographer always asks: “What’s the actual system here? What is missing from the map?”
This lens focuses on structure, boundaries, interdependence, hidden assumptions, dependencies, incentives, and brittle points. When reviewing a strategy, it asks what variables and constraints aren’t accounted for. When reviewing a deliverable, it asks whether the argument architecture is sound and what frame is missing.
The adversarial operator always asks: “How does this fail, get distorted, get resisted, or break under pressure?”
I specifically designed this lens to not be cynical. That’s an important design choice. A cynical critic produces dismissiveness. The Adversarial Operator is kind, reality-based, and focused on stress, misuse, resistance, failure modes, competitive pressure, and bad-faith response. It asks: where can this be attacked, misread, or dismissed? What naive assumption is hiding inside it? What reality would kill it?
The human interpreter always asks: “What happens when actual humans meet this?”
This lens focuses on cognition, trust, behavior, emotional friction, usability, and adoption reality. It exists because may sound things fail when in contact with human reality. A strategy can be architecturally perfect and still die because the people involved can’t use it, won’t adopt it, or misunderstand it.
This lens consistently produces observations about emotional texture that the other lenses miss: how something will feel to the reader, whether the cognitive load is manageable, whether trust is being built or undermined.
My private officer always asks: “What is the crux, and what is the move?”
This seat is the strategic synthesizer. It governs both the process and the conclusion. It doesn’t compete with the others, but it integrates them and decides what matters. Its focus is decision, compression, prioritization, and forward motion. Its job is to take the full picture, including disagreements between lenses, and produce the clearest possible recommendation.
I didn’t want lenses that overlap. The Systems Cartographer sees structure; the Adversarial Operator sees failure; the Human Factors Interpreter sees the collision between structure and real humans; the Private Officer synthesizes and moves.
Remove any one of them and the analysis has a blind spot. Add a fifth and it would either overlap with an existing lens or fragment the attention without adding a new dimension. Of course, I might make some changes, but for now, I’m quite happy with the design choice.
Of course, the skill doesn’t just define the lenses but also choreographs how they interact. This is the part that matters.
Step 1: Clarifying questions before any assessment
Before anyone runs the analysis or provides an opinion, each lens asks its own clarifying questions. Without this step, the analysis could run on something that might be misunderstood or mislabeled. I wanted to avoid this happening.
The protocol instructs Claude to skip clarifying questions when the context is already sufficient. That’s important too: unnecessary questions slow the process. The skill’s rule is simple: ask only what’s needed to avoid shallow or distorted judgment.
One thing worth noting: The Sonnet 4.6 model asks clarifying questions, but then proceeds with the analysis immediately, without waiting for my answers. The Opus 4.6 model asks the clarifying questions, then waits for my input before proceeding with the analysis. That’s why I always use this SKILL with the latter model.
Step 2: Independent assessments
Each lens assesses the object independently from its own perspective.
This is where the function-based design pays off. When you ask Claude to “consider multiple perspectives” in a single response, the perspectives blur into one balanced take. When you force four independent assessments, each from a defined function with a specific question it always asks, the outputs are genuinely different. Each lens produces observations the others missed, because each one is looking for different things.
Step 3: Cross-sharing and debate
The lenses respond to each other’s assessments, challenge, push back, or agree with each other. This is where the protocol generates its most valuable output: productive tension between perspectives that would otherwise collapse into consensus.
Step 4: Synthesis
The Private Officer integrates everything, surfaces remaining disagreements, and recommends the move.
Consensus is not required. The skill states this explicitly: “If meaningful disagreements remain, surface them clearly instead of forcing agreement.” This is a deliberate design choice. Forced agreement produces mush. Surfaced disagreement produces clarity about what the real trade-offs are.
The synthesis follows a consistent format: crux, main blind spots, main risks, recommended move, remaining disagreements, final recommendation. The format is tight because its job is to produce action, instead of ongoing analysis.
A prompt says: “Consider this from multiple angles.”
A skill says: here are the specific angles, each defined by a function it performs and a question it always asks. Here is the sequence: clarify first, then assess independently, then debate, then synthesize. Here is what happens when they disagree: disagreements are preserved. Consensus is not mandatory. Here is who makes the final call and how.
Prompts create one-shot responses. Skills create repeatable reasoning processes. I’ve run this SKILL dozens of times on different objects: my homepage copy, intel products, positioning decisions, document reviews, and the quality is consistent because the architecture is consistent.
Prompts rely on Claude’s default instincts about what “multiple perspectives” means. Skills focused on cognitive functions define the perspectives explicitly. Claude doesn’t have to guess what kind of thinking I want.
This SKILL is one instance of a more general design language.
Once you see this principle, you can build reasoning protocols for different kinds of work:
This is how you’re not asking Claude to be vaguely smart. Instead, you’re designing how intelligence is actually organized.
I didn’t expect much when I built this. I have no technical background and I felt anxious about creating a markdown SKILL for the first time. I didn’t know what to expect.
But after running this SKILL multiple times, something shifted. In a very compact format, I was getting things my own thinking couldn’t reach: blind spots I didn’t know I had, questions I hadn’t considered, perspectives that actually changed how I approached the problem, not just how I thought about it.
I’m still figuring out how to measure the full impact this has on my work. But I can say this: my reasoning became richer, and I feel more confident in what I do.